Go 的内存对齐
什么是内存对齐
现代计算机中内存空间都是按照字节(byte)进行划分的,所以从理论上讲对于任何类型的变量访问都可以从任意地址开始,但是在实际情况中,在访问特定类型变量的时候经常在特定的内存地址访问,所以这就需要把各种类型数据按照一定的规则在空间上排列,而不是按照顺序一个接一个的排放,这种就称为内存对齐(Memory Alignment),内存对齐是指首地址对齐,而不是说每个变量大小对齐。这种对齐方式可以提高内存访问的效率,特别是在访问大量数据结构时。
Go语言的内存对齐规则如下:
基本类型的对齐:基本类型的对齐要求通常是其字节大小。例如,
bool和int8类型对齐为1字节,int16类型对齐为2字节,int32和float32类型对齐为4字节,int64和float64类型对齐为8字节。结构体的对齐:结构体的对齐要求是其字段中的最大对齐值。每个字段的对齐值取决于字段的类型和先前字段的对齐值。如果结构体的对齐值大于字段的大小,则字段会按照对齐值进行填充。
内存分配的对齐:Go 语言中的内存分配是按照字节对齐的原则进行的,即每次分配的内存大小是对齐值的倍数。通常情况下,内存分配的对齐值是8字节。
内存对齐可以提高程序的性能,尤其是在访问结构体类型的字段时。如果结构体的字段没有正确对齐,会导致处理器需要进行额外的对齐操作,增加了内存访问的开销。
在Go语言中,可以使用 unsafe 包来进行内存操作,例如指针转换和内存布局控制。然而,需要注意的是,在使用 unsafe 包时需要特别小心,因为它涉及到底层的内存操作,可能导致不安全和未定义的行为。只有在必要时才应该使用 unsafe 包,并且要确保操作的正确性和安全性。
当涉及内存对齐时,可以使用以下图来说明对齐的概念:
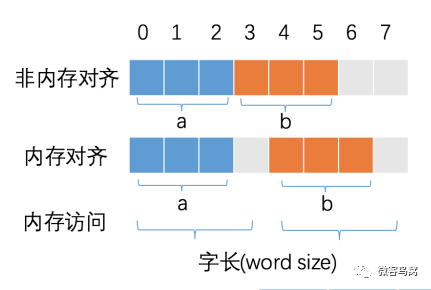
变量 a、b 各占据 3 字节的空间,内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节。
也可以看到,内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
简言之:合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
为什么内存对齐有好处?
为什么内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性?
内存访问的效率:处理器通常以特定的字节大小进行内存访问,称为“自然对齐”。当变量的起始地址与自然对齐的地址对齐时,处理器可以在一个内存读写操作中获取或修改整个变量的值。相比之下,如果变量未对齐,处理器需要进行多次读写操作来获取或修改变量的值,增加了额外的开销和访问延迟。
缓存行(Cache Line)的利用:现代计算机中,处理器的缓存以缓存行的方式工作。缓存行是一块连续的内存区域,一般为64字节或更大。当变量被加载到缓存中时,会以缓存行为单位进行操作。如果多个变量在同一个缓存行中,它们可以共享同一个缓存行,提高了内存读写的效率。通过内存对齐,可以将相关的变量放置在同一缓存行中,减少缓存行的浪费和缓存行间的竞争。
原子性操作的支持:有些处理器提供原子操作指令,可以保证某些操作的原子性,即这些操作不会被中断。对于原子操作来说,内存对齐是一个重要的前提条件。当变量的地址对齐时,原子操作可以以原子的方式读取或修改整个变量,而不会出现部分写入或读取的情况。
综上所述,内存对齐可以减少内存访问的开销和延迟,提高内存读写的性能。同时,它也有助于缓存的利用和原子操作的支持,使得变量操作更加可靠和高效。因此,良好的内存对齐可以对程序的性能和可靠性产生积极的影响。
struct 内存对齐的技巧
在设计结构体时,可以使用一些技巧来优化内存对齐,以减少内存浪费和提高性能。以下是一些常用的技巧:
将字段按照对齐要求从大到小排序:将字段按照对齐要求从大到小的顺序排列,可以最大程度地减少填充字节的数量。这样可以确保对齐要求较高的字段放置在前面,以减少后续字段的填充。
使用
struct嵌套:通过嵌套结构体,可以按照子结构体的对齐方式对整个结构体进行对齐。这样可以避免手动添加填充字节。
需要注意的是,内存对齐的优化应该根据实际的需求和特定的场景来决定。在进行结构体优化时,建议先进行性能测试和内存分析,以评估内存对齐的效果,并权衡内存占用和性能之间的权衡。
编译器已经对变量做了内存对齐,程序员可以通过调整成员变量顺序减少结构体占用大小,节省内存,对内存很敏感的场景还是有必要做的,如果对内存不敏感,记住一个大原则:将大的变量放在前面,如果你完全不 care 性能,则可以略过此篇文章。
有人可能会问,编译器能把内存对齐的工作做了,为什么不接着在编译期把结构体成员变量顺序优化呢?这样可以降低程序员的心智负担。
如果编译器自动优化了结构体成员变量顺序,数据经过网络传输后怎么能正确的还原回原来的结构体呢?
实际的例子
当定义一个结构体时,内存对齐的规则会自动应用于结构体的字段。下面是一个示例:
package main
import (
"fmt"
"unsafe"
)
type Example struct {
A bool
B int32
C float64
}
func main() {
example := Example{
A: true,
B: 42,
C: 3.14,
}
size := unsafe.Sizeof(example)
offsetA := unsafe.Offsetof(example.A)
offsetB := unsafe.Offsetof(example.B)
offsetC := unsafe.Offsetof(example.C)
fmt.Printf("Size of Example struct: %d bytes\n", size)
fmt.Printf("Offset of A: %d bytes\n", offsetA)
fmt.Printf("Offset of B: %d bytes\n", offsetB)
fmt.Printf("Offset of C: %d bytes\n", offsetC)
}
在上面的示例中,我们定义了一个名为 Example 的结构体,它包含三个字段:A 为 bool 类型,B 为 int32 类型,C 为 float64 类型。
使用 unsafe.Sizeof() 函数可以获取 Example 结构体在内存中的总大小。通过 unsafe.Offsetof() 函数可以获取结构体中每个字段的偏移量。
在常见的64位机器上,上述示例输出的结果可能如下:
Size of Example struct: 16 bytes
Offset of A: 0 bytes
Offset of B: 4 bytes
Offset of C: 8 bytes
从输出可以看出,Example 结构体的大小为16字节,字段 A 的偏移量为0字节,字段 B 的偏移量为4字节,字段 C 的偏移量为8字节。
这是因为布尔类型的大小为1字节,但由于对齐规则要求字段的起始地址是其大小的倍数,所以字段 A 和字段 B 之间填充了3字节的空间,以使 int32 类型字段对齐。同样地,字段 B 和字段 C 之间填充了4字节的空间,以使 float64 类型字段对齐。
通过内存对齐,保证了结构体中字段的访问效率和正确性。